Een vaak onderbelicht onderdeel van ontwikkelen voor het web is wat er gebeurt nadat je website of webapplicatie live is gegaan. Bij Netvlies zeggen we altijd: de livegang is pas de start! Om de resultaten van je website of webapplicatie te kunnen verbeteren en tijdig te kunnen reageren als er iets mis is, is het belangrijk dat je inzicht hebt in hoe deze presteert. Niet alleen qua bezoekersaantallen en conversie, maar ook op het gebied van laadtijden, belasting van de server, de werking van de koppelingen met externe systemen, en steeds belangrijker: security. In dit blog vertellen we wat meer over onze zoektocht naar nieuwe monitoring-tools en hoe we onze monitoring uiteindelijk hebben ingericht.
Het monitoren van een website of webapplicatie is natuurlijk niet nieuw, alleen gebeurt dit doorgaans alleen op het vlak van netwerk, hardware en middleware. Dat een webserver goed werkt geeft geen zekerheid of een bedrijfskritische functionaliteit ook écht werkt. Daarom wilden we ook specifieke functionaliteiten kunnen monitoren zoals de werking van belangrijke formulieren en onderdelen zoals datakoppelingen met externe systemen. Ongeacht of wij voorzien in de hosting of dat via een andere leverancier gaat of de servers bij de klant intern staan. En dat alles gecombineerd op één klantdashboard dat we ook delen met onze klanten.

Voor onze monitoring maakten we al geruime tijd gebruik van Nagios. De inrichting en het beheer hiervan is echter erg tijdsintensief. De slechte interface en rommelige configuratie in combinatie met onze wens om méér te gaan monitoren dan alleen hardware en middleware, maakt dat we op zoek zijn gegaan naar nieuwe tools en mogelijkheden.
De nieuwe monitoring-tool moest minstens voldoen aan de volgende randvoorwaarden:
beschikbaarheid van app (iOS/Android) voor alarmen/waarschuwingen;
mogelijkheid om zelf checks te definiëren;
eenvoudige configuratie;
data toegankelijk via API of database-koppeling;
alarm/waarschuwing toekennen aan bepaald persoon;
geen SAAS/cloud oplossing. Onze data is van ons!
Er zijn ontelbaar veel tools beschikbaar...om er maar eens een paar te noemen: Nagios, Icinga, Flapjack, Cabbix, Gacti, Graphite, Grafana, Kibana, … en nog veel meer. Echter geen van deze tools lijkt aan ál onze eisen te voldoen. We kwamen dus al snel tot de conclusie dat een combinatie van meerdere tools nodig was, een zogenaamde “stack”. Omdat er bij het gebruik van meerdere tools ook een zekere overlap in functies ontstaat hebben we goed gekeken naar hoe we de verantwoordelijkheden per tool kunnen opsplitsen (het “separation of concerns” principe).
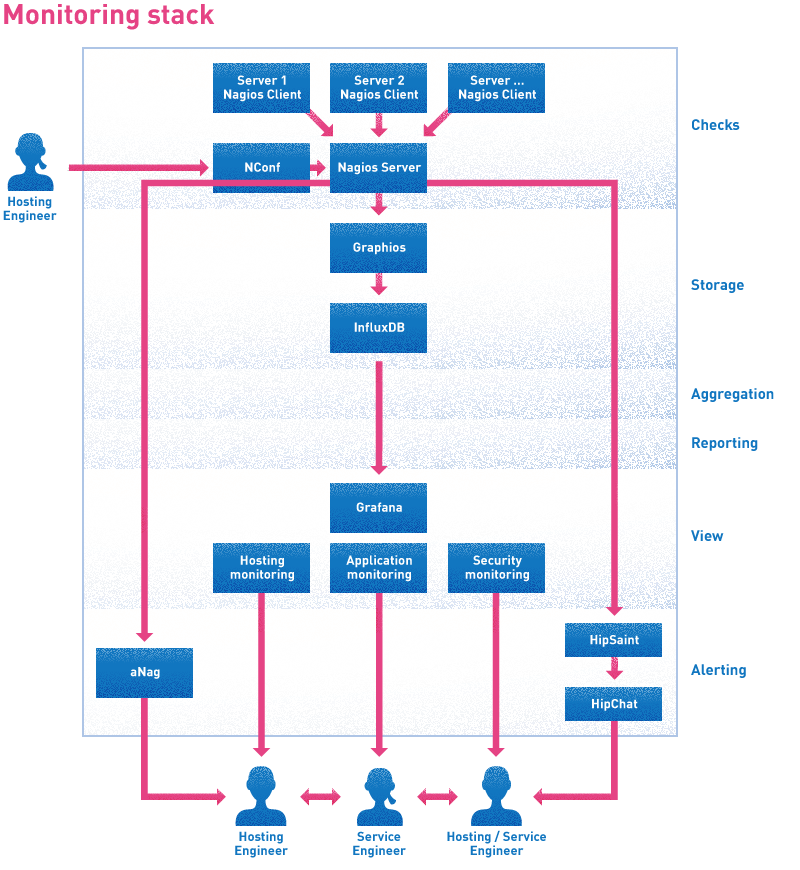
Door de mogelijkheden van verschillende tools te combineren hebben we de volgende functionele indeling / opsplitsing voor onze “monitoring stack” gemaakt:
Checks
Verzamelen van data / meetwaarden
Storage
Opslag van ruwe data / meetwaarden
Aggregation
Interpreteren, combineren van data en deze inzichtelijk maken
View
Weergave van de data
Alerting
Signaleren wanneer actie benodigd is
Reporting
Rapportage t.b.v. goed gefundeerde keuzes in de toekomst
Door deze opsplitsing is het eenvoudig om per laag de juiste oplossing/tool te selecteren. Hieronder zie je hoe we onze monitoring stack nu hebben ingevuld, en ook per onderdeel waarom we voor die specifieke invulling hebben gekozen.
View
Voor de weergave van data zijn verschillende combinaties van toolstacks beschikbaar. Erg mooi zijn de al langer bestaande ELK-stack (Elasticsearch, Logstash, Kibana) en de TICK-stack (Telegraph, Influxdb, Chronograf, Kapacitor). Er is echter ook een nieuwe speler op de markt: Grafana. Deze tool is in één woord: geweldig. Met Grafana beschik je over een makkelijk te configureren dashboard dat bijna realtime data kan tonen vanuit verschillende bronnen. De keuze voor Grafana voor de visualisaties was dus snel gemaakt.
Checks / Storage
Omdat we +/- 50 servers in beheer hebben en checken met Nagios, en we deze niet allemaal opnieuw willen configureren hebben we ervoor gekozen om voor de checks Nagios te blijven gebruiken. De meetwaarden die dit oplevert willen we opslaan in een handig en acceptabel formaat, zodat we deze straks makkelijk kunnen tonen en bewerken. Voor de opslag hebben we gekozen voor InfluxDB. InfluxDB is prima geschikt voor de opslag van meetwaarden, beschikt standaard over een aantal voorgedefinieerde retentieschema’s en wordt goed ondersteund door Grafana, de tool die we voor onze view-laag geselecteerd hebben.
Na onze keuze voor opslag moest er nog wel wat gedaan worden om de data die Nagios oplevert ook daadwerkelijk in de InfluxDB database te krijgen. We maken hiervoor gebruik van Graphios.
We blijven dus voor de checks gebruik maken van Nagios. Aan het begin van dit blog vertelde ik al dat de inrichting en beheer van Nagios erg tijdsintensief is. Om die pijn wat te verzachten hebben we Nconf geïnstalleerd om de Nagios configuratie mee te beheren. Met Nconf kunnen we elke check, host, command, etc. via een webinterface beheren, en hierbij ook gebruik maken van verschillende templates. Vervolgens kunnen we met één klik de configuratie genereren die we na een controle direct kunnen deployen naar de Nagios runtime. Het heeft wat tijd gekost om alle bestaande configuraties in Nconf te krijgen, maar dat was de moeite zeker waard omdat we nu in een paar seconden een nieuwe server aan de configuratie kunnen toevoegen.
Aggregating/Reporting
Op dit moment hebben we nog geen use-cases waarbij het combineren van data en deze inzichtelijk maken gewenst en/of heel bruikbaar is, maar wanneer dit straks wel het geval is zullen we waarschijnlijk gebruik gaan maken van Logstash. Voor uitgebreide rapportage hebben we nog niet echt de keuze gemaakt voor één tool. Deze keuze laten we afhangen van wat de klant hierin wenst. Door gebruik te maken van InfluxDB voor de dataopslag kunnen we voor rapportage alle kanten op, want er zijn veel verschillende rapportagetools die kunnen inhaken op InfluxDB en hier alle benodigde info uit krijgen.
Alerting
Om ook op afstand te kunnen monitoren en een seintje te krijgen wanneer er iets niet goed gaat gebruiken we een app: aNag (Helaas op dit moment alleen nog voor Android-devices).
aNag werkt perfect voor het melden van een alarm, maar hier kun je vervolgens geen acties aan koppelen, of deze bespreken met andere hosting- en/of service-engineers. Hier hebben we een oplossing voor gevonden in de vorm van HipChat. In HipChat kun je de alarmen van al je systemen “dumpen” en deze vervolgens delegeren aan de juiste persoon. Ook kun je hier een bepaalde status aan een alarm geven, zoals bijvoorbeeld “gezien”, “bezig met oplossing”, etc. Om HipChat aan Nagios te koppelen gebruiken we HipSaint.
Conclusie
Er bestaat niet één supertool die álles kan wat monitoring betreft. Accepteren dat je een combinatie van tools, een “stack” moet maken om aan al je monitoring-wensen te voldoen is stap 1. Ze op de juiste manier inrichten en aan elkaar koppelen is stap 2. We zijn ervan overtuigd dat we met onze stack een complete en indrukwekkende monitoring-oplossing in huis hebben. We nodigen iedereen dan ook uit om als je bij Netvlies op bezoek bent even te spieken op split-level waar onze zelfgebouwde monitor-wall staat. Je krijgt zo direct een goed beeld van wat we allemaal doen om je website, social intranet, portaal of webapplicatie na livegang goed in de gaten te houden, want onthoud: “de livegang is pas de start!”.
En niet onbelangrijk, de nieuwe monitoring zorgt voor een hogere kwaliteit. Het geeft daarbij onze klanten ook beter inzicht in de manier waarop wij hun oplossing in de gaten houden en onderhouden. Door zoveel mogelijk geautomatiseerd te monitoren zorgen we voor een robuuste en veilige online oplossing en voorkomen we omzetderving die downtime met zich mee kan brengen.
De technische uitleg is gebaseerd op het eerder gepubliceerde artikel op mijn persoonlijke blog (Engelstalig): https://markri.nl/custom-monitoring-stack.